
首頁 /
透事 Thoughts

穿越文字,即刻透事
「透事」為藍星球團隊淬鍊多年,獨家開發的文字探勘技術成果。透事可在短時間內以「智慧分類」、「自動摘要」、「詞彙萃取」、「情緒感測」、「猜你喜歡」、「觀點聚類」等6大元件分析不同來源之中文文本資料,協助您精準掌握重要資訊、進一步發掘資料價值,讓資料驅動引導您走向更廣闊的未來。
多年文字探勘累積的研發成果
藍星球擁有業界最豐富的文字探勘經驗,我們致力於替每位客戶從巨量文本數據中,挖掘出最富價值的資訊。無論是網路輿情監測、商業授信分析,抑或是各式非結構化資料處理,我們都能協助您探索其中的洞見與關係。
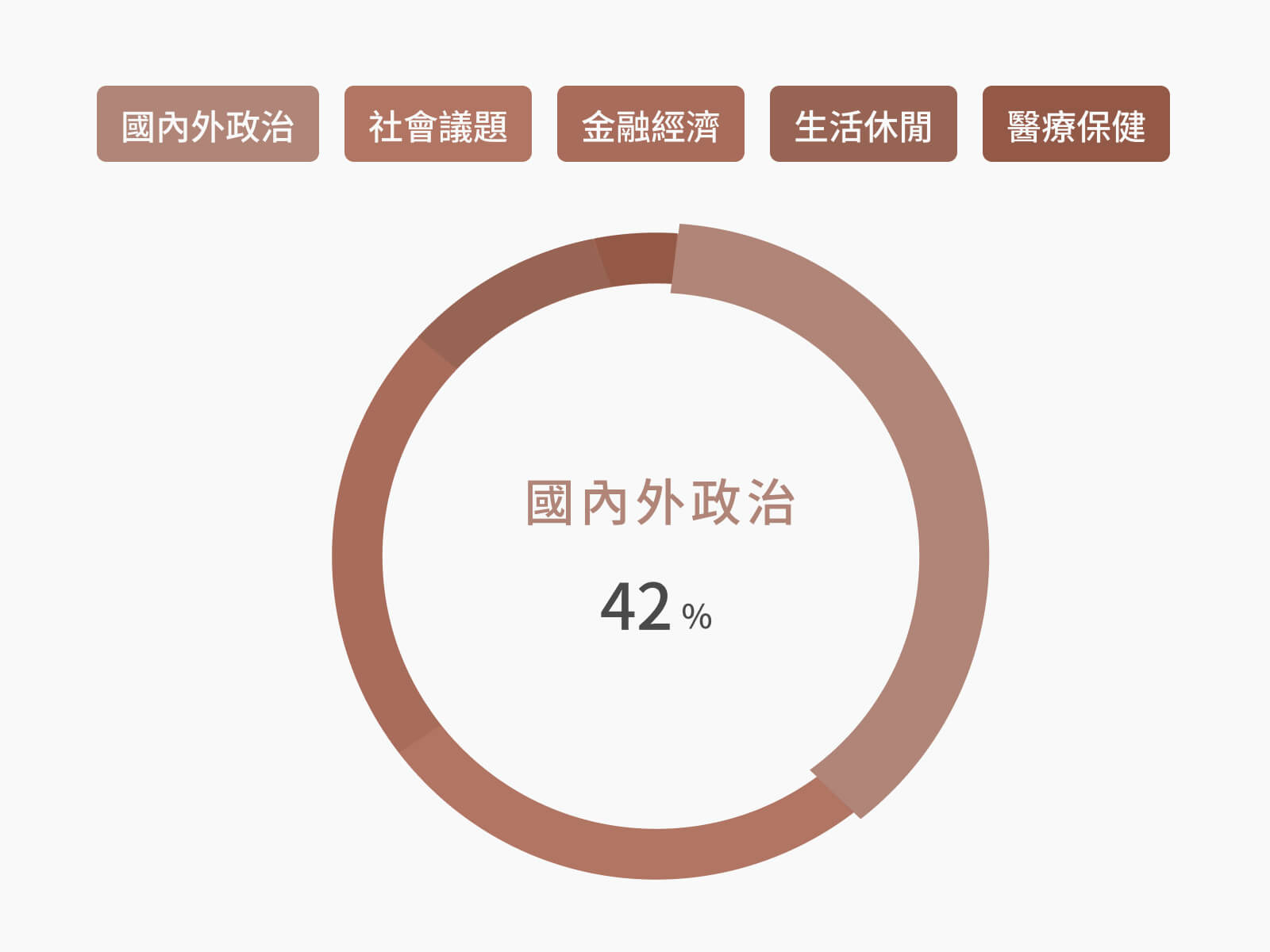
智慧分類
快速辨識文本內容、自動分門別類;以輿情資料為例,可精準判斷討論主題屬於政治社會、生活休閒、金融經濟等何種類型。
自動摘要
採句子重要性評分運算,將長篇文章拆解為句子型式子單位,換算句子在文章中的位置、句子構成特徵、與文章其他句子於向量空間的相對距離關係,以此得出每個句子在文章向量空間的重要程度,再由文章重組模型參照重要程度重新產出具高可讀性的20%、50%、80%摘要內容。


詞彙萃取
以機器學習為基礎,透過解構句子內的最小實體單位、大量學習文章用語樣式(pattern),自動化萃取文本中的人物、組織團體、地點、企業品牌、關鍵字等詞彙。
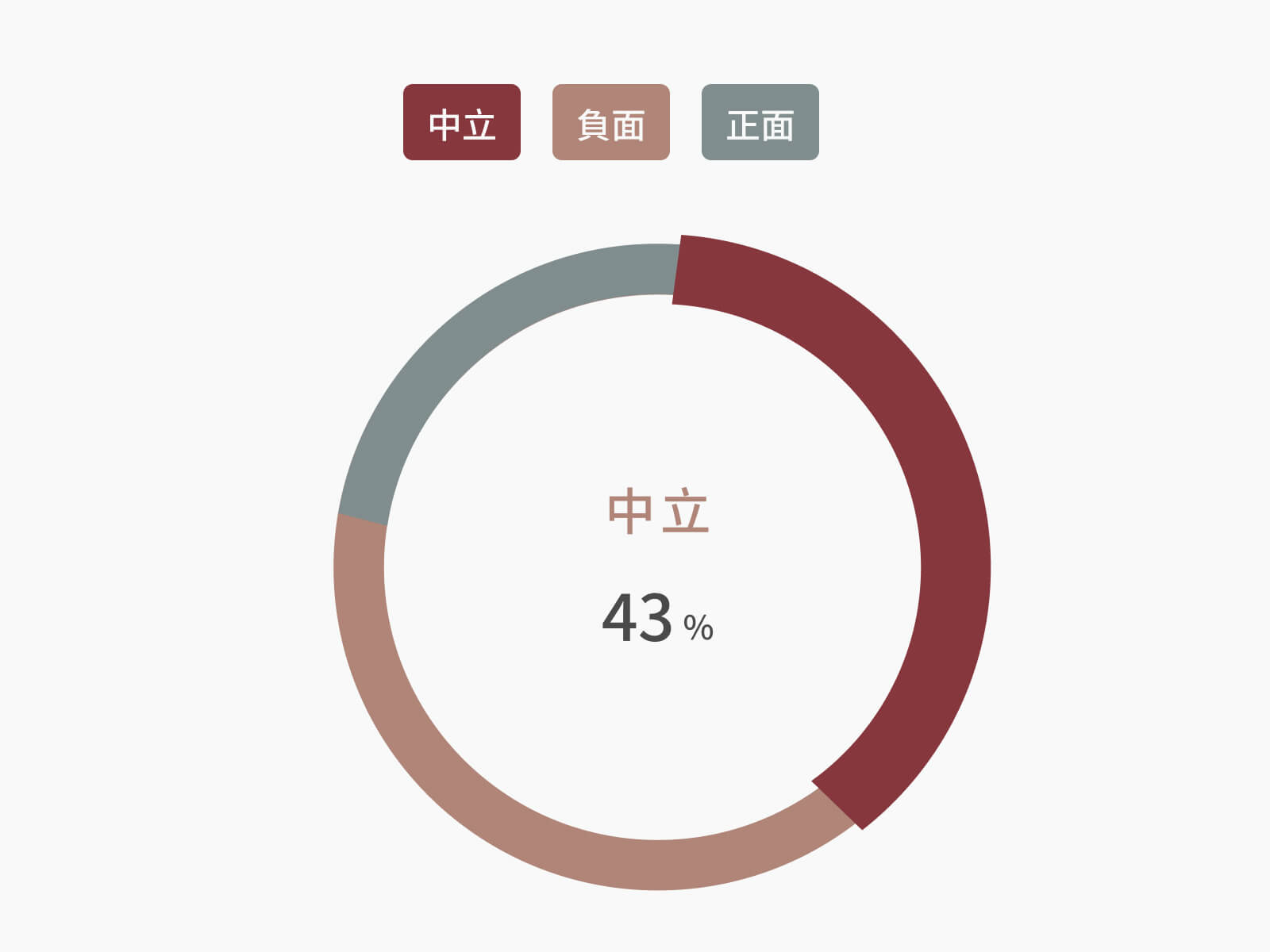
情緒感測
針對中文文本的情緒判讀主要是透過改良長短期記憶網路(LSTM)方法、調整忘卻閥(forget gate)Sigmoid層函數,同時導入藍星球中文標註參照集,強化篩選前次傳入的訊息特徵後,用以判斷該訊息是否具備某些隱藏特徵,例如詞語挪用機率、語境分類等,從而提升判讀準確率。

猜你喜歡
彙整巨量資料,依據文本內容,進行文本詞彙間的關聯運算。提供使用者可能喜歡的內容。
觀點聚類
透過巨量資料的剖析,將相似內容分別歸納為各個群聚、轉為分群問題,可應用於多筆評論資料,無論當前數種觀點風向、討論熱度為何,皆能全盤掌握。
我們的客戶
最新消息及線上資源
-

AI Agent 是未來 AI 核心?從電影製作流程看懂技術架構
對於 AI Agent(人工智慧代理)的底層技術,你是否總有一種似懂非懂的模糊感…
-

投資公司是什麼?節稅原理、5大好處與設立流程一次解析
一、投資公司是什麼?成立前的核心評估重點有哪些? 在資產規模逐漸成長後,許多投資…
-

藍星球資訊進化倫「大溝溪淨山X生態縱走」
AI 做不到的事 需要大家一起來守護 5/1勞動節連假台北市環保局舉辦「大溝溪淨…